Amazon Bedrock Knowledge Bases: Uwolnij Potencjał Wiedzy Przedsiębiorstwa w Generatywnej AI
W erze rosnącej popularności sztucznej inteligencji, firmy poszukują sposobów na włączenie swoich unikalnych danych i wiedzy do potężnych modeli generatywnych. Problem polegał często na tym, że duże modele językowe (LLM) są trenowane na ogólnodostępnych danych i brakuje im specyficznego kontekstu biznesowego, co prowadziło do nieprecyzyjnych lub nieadekwatnych odpowiedzi. Amazon Bedrock Knowledge Bases (bazy wiedzy) to odpowiedź na to wyzwanie, oferując bezpieczny i skalowalny sposób na rozszerzenie możliwości LLM-ów o własne, zastrzeżone informacje.
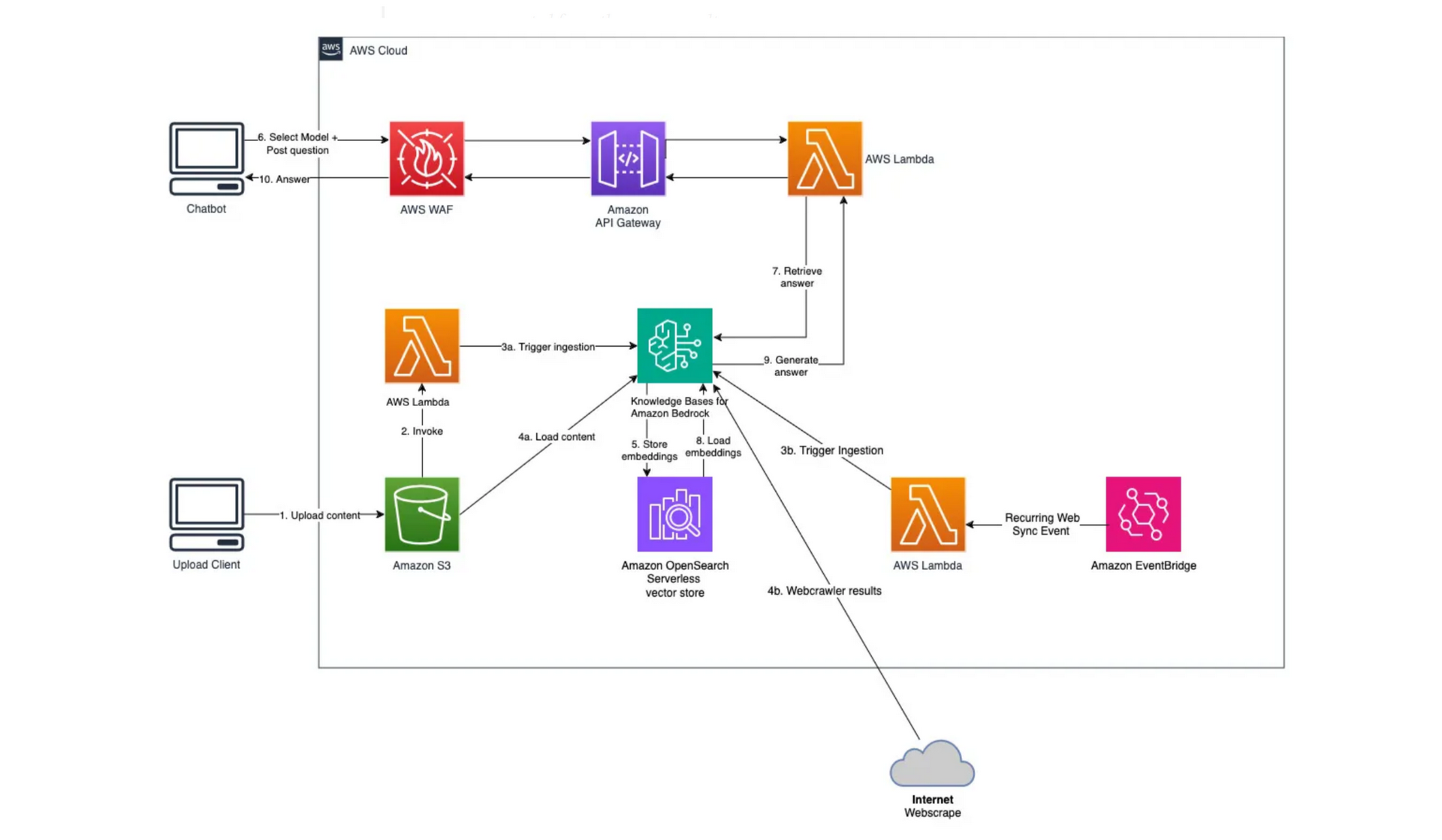
Jak to działa?
Proces jest stosunkowo prosty:
-
Ładowanie Danych: Dane mogą pochodzić z różnych źródeł, takich jak (dokumenty PDF, Word, pliki tekstowe, HTML), bazy danych, systemy CRM, wiki korporacyjne czy wewnętrzne portale.
-
Indeksowanie i Wektoryzacja: Bedrock automatycznie przetwarza Twoje dokumenty, dzieli je na mniejsze fragmenty (chunks), a następnie przekształca w wektory. Te wektory są przechowywane w bazie danych wektorowej (np. Amazon OpenSearch Serverless, Pinecone, Redis). Wektoryzacja pozwala na szybkie i efektywne wyszukiwanie semantyczne.
-
Zapytanie Użytkownika: Gdy użytkownik zadaje pytanie, Bedrock najpierw wektoryzuje to pytanie.
-
Wyszukiwanie Kontekstu: Następnie wyszukuje w bazie wektorowej fragmenty dokumentów, które są semantycznie najbardziej zbliżone do zapytania użytkownika.
-
Generowanie Odpowiedzi: Odnalezione fragmenty (kontekst) są przesyłane do wybranego modelu fundamentowego (np. Anthropic Claude, AI21 Labs Jurassic, Amazon Titan) wraz z oryginalnym zapytaniem. Model wykorzystuje ten kontekst do sformułowania precyzyjnej i rzetelnej odpowiedzi.
Kluczowe Korzyści:
-
Zwiększona Trafność: Odpowiedzi są znacznie bardziej trafne i specyficzne, ponieważ opierają się na faktycznych danych firmy, a nie na ogólnej wiedzy modelu.
-
Redukcja Halucynacji: Dzięki dostarczaniu autorytatywnego kontekstu, ryzyko generowania przez LLM nieprawdziwych informacji (tzw. "halucynacji") jest znacznie zredukowane.
-
Aktualność Informacji: Baza wiedzy może być regularnie aktualizowana, co oznacza, że odpowiedzi LLM zawsze będą bazować na najnowszych dostępnych danych.
-
Bezpieczeństwo i Prywatność: Dane pozostają pod kontrolą klienta i nie są wykorzystywane do treningu bazowego modelu fundamentowego, co jest kluczowe dla zachowania poufności.
-
Łatwość Integracji: Upraszcza proces budowania aplikacji RAG, eliminując potrzebę samodzielnego zarządzania złożonymi potokami danych i bazami wektorowymi.
-
Cytowanie Źródeł: Użytkownicy mogą otrzymać linki do oryginalnych dokumentów, z których pochodzą informacje, co zwiększa zaufanie i weryfikowalność odpowiedzi.
Przykładowe Zastosowania:
-
Obsługa Klienta: Chatboty i wirtualni asystenci mogą odpowiadać na pytania klientów, bazując na dokumentacji produktowej, politykach firmy i FAQ.
-
Wsparcie Pracowników: Wewnętrzne narzędzia AI mogą pomagać pracownikom w szybkim odnajdywaniu informacji o procedurach HR, politykach firmy czy wewnętrznych instrukcjach technicznych.
-
Analityka Biznesowa: Generowanie raportów i analiz na podstawie wewnętrznych danych finansowych, rynkowych czy operacyjnych.
-
Badania i Rozwój: Szybkie przeszukiwanie ogromnych zbiorów danych badawczych i dokumentacji technicznej w celu przyspieszenia innowacji.
Amazon Bedrock Knowledge Bases to potężne narzędzie, które otwiera drzwi do budowania inteligentnych aplikacji generatywnej AI, które nie tylko rozumieją, ale i efektywnie wykorzystują unikalną wiedzę każdej organizacji. To klucz do tworzenia bardziej precyzyjnych, wiarygodnych i wartościowych rozwiązań AI.
Czym jest Amazon Bedrock Knowledge Bases?
Amazon Bedrock Knowledge Bases to w pełni zarządzana usługa, która pozwala firmom łączyć własne dane z modelami fundamentowymi (FMs) dostępnymi w Amazon Bedrock. Zamiast zmuszać LLM-a do "zapamiętywania" całej Twojej dokumentacji (co jest nieefektywne i kosztowne), Knowledge Bases wykorzystuje technikę Retrieval Augmented Generation (RAG). RAG polega na pobieraniu istotnych fragmentów informacji z Twojej bazy wiedzy, a następnie przekazywaniu ich do LLM-a wraz z zapytaniem użytkownika. Dzięki temu LLM może generować odpowiedzi oparte na aktualnej, autorytatywnej i specyficznej dla Twojej firmy wiedzy.